Dalton Malmin | December 3rd, 2024
When you’re scrolling through your favorite online retailer — Amazon, eBay, or maybe even the Vanderbilt Bookstore for next semester’s textbooks — there’s so much more happening behind the screen than the simple list of products you see. Behind it all are algorithms, invisible aides busy shaping your shopping experience, whether you’re searching for course materials or just browsing for new items. They decide what items pop up on your screen, suggest products you might be interested in, and sometimes dynamically transform prices instantly. These algorithms, it might feel like, create a shopping experience that feels tailored to you.
Let’s break down how this works.
The power of personalization
Every click you make and every online item you view cumulatively feeds into an algorithm designed to learn more about what type of products you like. This is how a recommendation system essentially works: it examines your browsing behavior and suggests products you might like based on observed patterns.
A popular algorithmic approach to these recommendation systems is something known as item-based collaborative filtering. In this approach, algorithms calculate the similarity between different products based on user interactions and ratings. One common way to measure the similarity between two items is by using the Pearson correlation coefficient, which compares how users rate those items.
The formula for the Pearson correlation similarity between two items, i and j, looks like this:
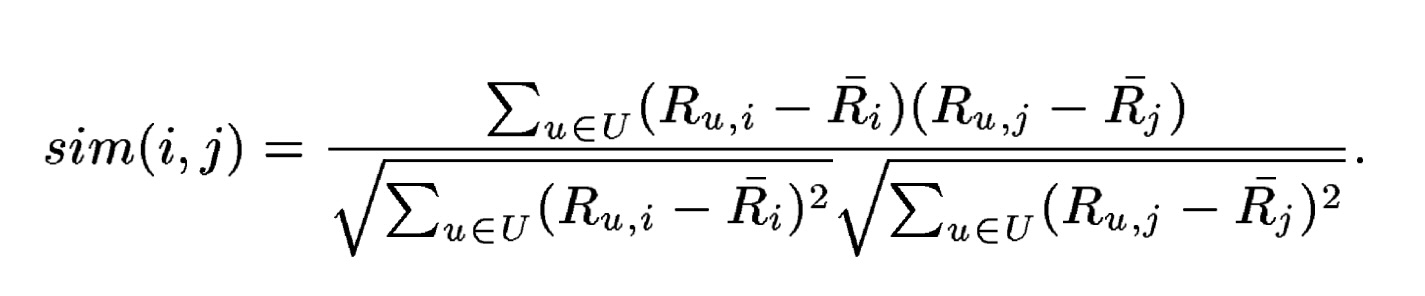
Here’s what it means:
- sim(i, j) denotes the similarity between items i and j.
- Ru,i and Ru,j denote the rating of user u on items i and j, respectively.
- Ri and Rj denote the average rating of the i-th and j-th items, respectively.
- U is the set of users who have rated both items.
Now, if you’re thinking, “That looks like a lot,” you’re not wrong! Though, in essence, and much more concisely, all this equation is effectively doing is comparing how people rate products and then deriving patterns. In practice, this means that if two items consistently receive similar ratings from multiple users, they are deemed similar by the algorithm. So, if you enjoy a particular pair of shoes, for example, the system might suggest a different pair that has been rated similarly by others who like the first pair.
Search algorithms: Ranking products by relevance
The search feature is another integral part of the shopping experience shaped by algorithms. For example, a Vanderbilt student looking for textbooks or university apparel may notice how the Vanderbilt Bookstore website ranks products based on relevance to their specific query. One widely used method for this task is the TF-IDF (Term Frequency-Inverse Document Frequency) measure, which scores items based on how often your search terms appear in the product descriptions and how important those terms are across all products.
The TF-IDF score for a query q and a product d is:
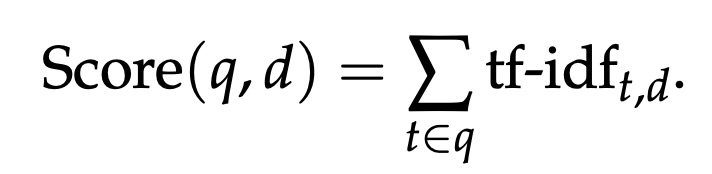
This equation means that the total relevance score of a product d for your search query q is the sum of the TF-IDF values for each term t in your query. Now, let’s break down the two key components of TF-IDF:
- Term Frequency (TF): This measures how often a specific term t appears in the product description d. The idea is simple: the more times a term appears in a description, the more relevant the product might be for that term.
- Inverse Document Frequency (IDF): This downweights terms that are too common across all products. Words like “the” or “shoes” might appear everywhere, so IDF helps to reduce the importance of these common terms. It is calculated as:
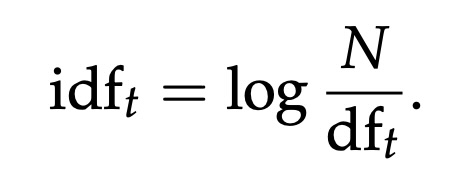
- N is the total number of products.
- dft is the number of products containing the term t.
Let’s say you search for “running shoes.” The algorithm calculates how often those words appear in each product’s description (term frequency) and how rare or common they are across all products (inverse document frequency). Products that frequently mention both “running” and “shoes” but aren’t overly generic are ranked higher in your search results.
Combining algorithms for a better experience
Many online retailers and platforms use recommendation algorithms such as Pearson correlation and search algorithms such as TF-IDF in conjunction. Because of this, when you search for a product, the platform doesn’t just present you with relevant results but might also recommend similar items based on what you’ve clicked or purchased before. This combination of search and recommendation algorithms is why you might feel your shopping experiences are personalized.
Ethical considerations: Balancing convenience and privacy
While algorithms may enhance the online shopping experience by personalizing your recommendations and tailoring your search results, they also raise ethical concerns around privacy and equity. The truth is that these systems rely on expansive amounts of personal data, often collected without the user fully understanding how it’s being used. However, privacy concerns are just one piece of the puzzle; the real issue lies in how algorithms can perpetuate societal biases. As Cynthia Dwork, a professor of computer science at Harvard, and Deirdre Mulligan, a professor in the school of information at UC Berkeley, argue in a publication for the Stanford Law Review, that the risks of classification and segmentation — where algorithms sort and target users based on their data — can lead to discrimination and “filter bubbles,” which limit exposure to diverse perspectives and restrict autonomy. This categorization process based on identifying users through correlation may inadvertently produce unequal outcomes, such as biased product recommendations or differential pricing, reinforcing social inequalities. So, although these algorithms offer convenience and personalization, users should stay aware of their broader effects — especially regarding privacy concerns and the potential to reinforce existing societal biases.
References
Dwork, C., & Mulligan, D. K. (2019, April 30). It’s Not Privacy, and It’s Not Fair. Stanford Law Review. https://www.stanfordlawreview.org/online/privacy-and-big-data-its-not-privacy-and-its-not-fair/
Manning, C. D., Raghavan, P., & Schütze, H. (2008). Introduction to Information Retrieval. Cambridge: Cambridge University Press. https://doi.org/10.1017/CBO9780511809071
Sarwar, B., Karypis, G., Konstan, J., & Riedl, J. (2001, April 1). Item-based collaborative filtering recommendation algorithms. ACM Digital Library. https://doi.org/10.1145/371920.372071